 Less effort,
Less effort, Cutting edge big data
Cutting edge big data Connect everything,
Connect everything, Open,
Open,เริ่มต้นกำหนดทิศทางธุรกิจ
ด้วยข้อมูลในมือคุณ
เริ่มต้นกำหนด
ทิศทางธุรกิจ ด้วย
ข้อมูลในมือคุณ
ทิศทางธุรกิจ ด้วย
ข้อมูลในมือคุณ
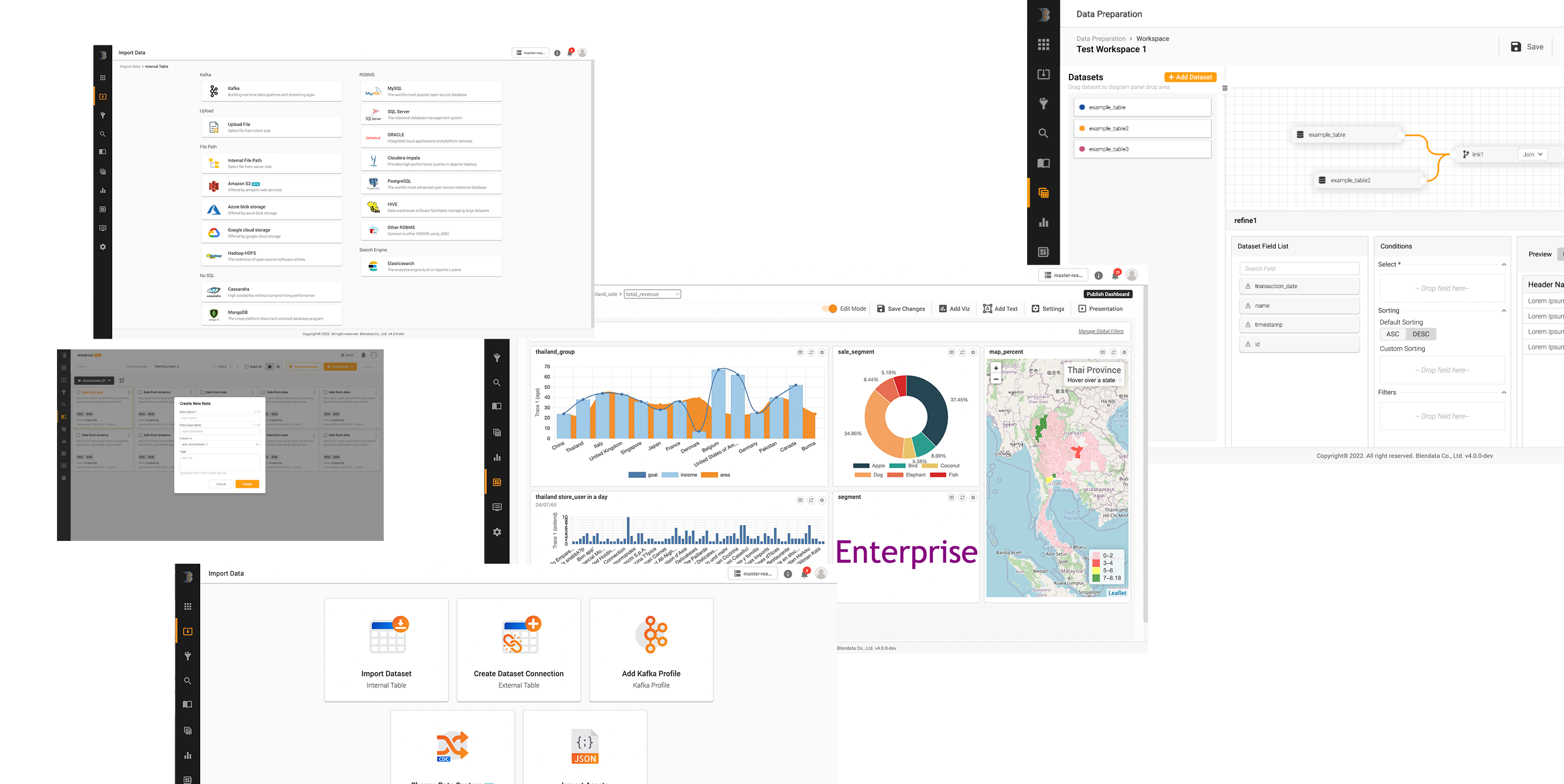




ลดความซับซ้อนในการจัดการข้อมูลและลดเวลาในการติดตั้งระบบ สามารถบริหารจัดการทุกขั้นตอน ตั้งแต่การรวบข้อมูล (Integrate) จนถึงการนำข้อมูลไปใช้งาน (Utilize) ได้ในแพลตฟอร์มเดียว จึงเป็นเครื่องมือที่ตอบตั้งแต่การให้ Engineer เชื่อมข้อมูล ไปจนถึงให้ User ใช้ข้อมูล ในแบบ Low-code/No-code ซึ่งไม่ต้องมีความรู้ด้านการเขียนโค้ดก็สามารถใช้งานได้
บอกลาการขยาย Big data โดยการขยายเซิฟเวอร์ทีละเครื่อง แพลตฟอร์มนี้ทำงานบนสถาปัตยกรรมยุคใหม่อย่างการแยกส่วนหน่วยคำนวณและการจัดเก็บข้อมูล (Decoupling compute & storage) รวมถึงหน่วยประมวลผลคู่ขนานแบบกระจายตัว (Distribute in-memory processing) เอกสิทธิของ Blendata ซึ่งพัฒนาต่อยอดบนพื้นฐานของ Apache Spark ที่มีความเร็วในการประมวลผลมากกว่าอย่างน้อย 1.5 เท่า
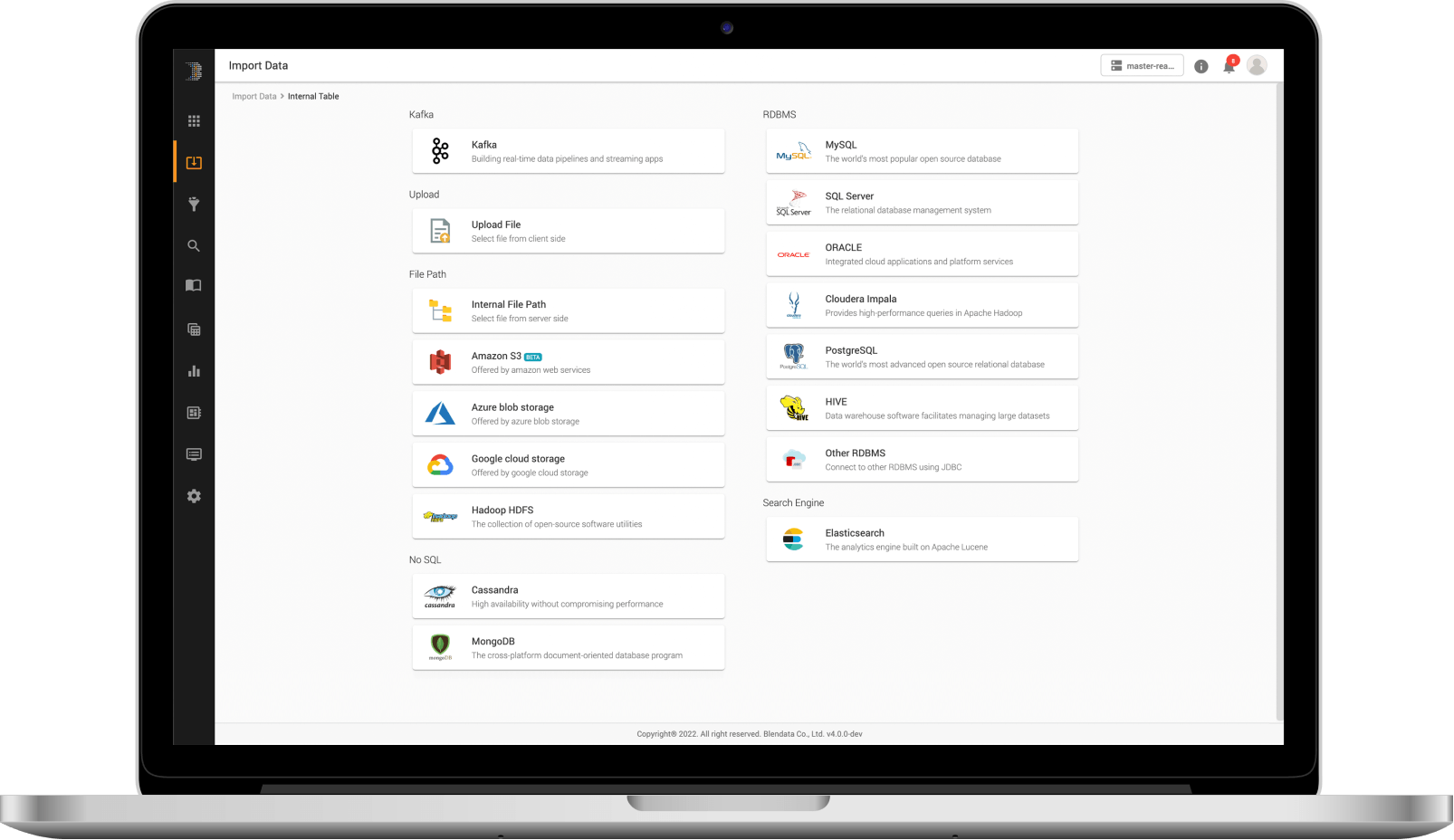
สามารถเชื่อมต่อข้อมูลได้อย่างหลากหลายตั้งแต่ Structured, Semi-structured, และ Unstructured (Text-based) ไม่ว่าจาก Cloud storages อย่าง Amazon S3, Azure Blob หรือ On-premises environment เช่น Flat files (CSV, JSON, Text), Logs, Kafka, HDFS หรือ Enterprise databases (Oracle, MS SQL Server, MongoDB, และอื่น ๆ) ผ่านรูปแบบการดึงข้อมูลที่หลากหลาย (Dynamic data ingestion)
ด้วยรูปแบบแพลตฟอร์มแบบเปิด (Open platform) องค์กรจึงสามารถใช้งานข้อมูลหรือฟังก์ชันของแพลตฟอร์มผ่าน API ที่รองรับตั้งแต่ REST API, ODBC/JDBC หรือเข้าถึงข้อมูลโดยตรงผ่านไฟล์ที่เก็บอยู่ในรูปแบบ Open format ทั้งนี้ ทุก ๆ การเชื่อมต่อ การขนย้ายข้อมูล (In-transit) รวมถึงข้อมูลที่ถูกจัดเก็บ (at-rest) สามารถป้องกันการเข้าถึงโดยมิชอบได้โดยการเข้ารหัสข้อมูลแบบ Column encryption การเข้ารหัสการสื่อสาร (In-transit encryption) ด้วยมาตรฐานอย่าง SSL/TLS รวมไปถึงระบบ Authentication, Authorization ในรูปแบบ User/Role-based access control มาตรฐาน OAuth2.0




เชื่อมต่อข้อมูลได้หลากหลาย
สามารถเชื่อมต่อและรวบรวมข้อมูลได้จากทุกแหล่งที่มา ไม่ว่าจะเป็น Flat files (CSV, JSON, Plain text, Parquet ฯลฯ ), Databases (Oracle, MS SQL, MySQL ฯลฯ ), Cloud และ Stream ผ่าน Connectors ในตัวแพลตฟอร์ม โดยไม่ต้องเขียนโค้ด
การนำเข้าข้อมูลแบบไดนามิก
นำเข้าข้อมูลจาก Flat files, Log, Databases หรือ Cloud storage ได้แบบอัตโนมัติผ่าน Connectors ในตัวแพลตฟอร์ม โดยวิธีการดังต่อไปนี้
– Scheduled replication (Batch/Stream)
– Data virtualization
– Changed data capture (CDC)
แปลงข้อมูลได้ทันทีระหว่างการนำเข้าข้อมูล (ETL)
สามารถทำการแปลงข้อมูลได้ในทันทีระหว่างการนำเข้าข้อมูล ด้วย Spark SQL พร้อมชุดฟังก์ชันการแปลงข้อมูลที่หลากหลายเพื่อรองรับข้อมูลจำนวนมหาศาล
สร้าง Schema ที่เหมาะสมกับข้อมูลได้แบบอัตโนมัติ
Engine ของ Blendata จะช่วยในการค้นหาคุณลักษณะและสร้าง Schema ได้โดยอัตโนมัติ สำหรับทุกตารางการนำเข้าข้อมูล ไม่ว่าจะเป็น File, Databases หรือการสตรีมผ่าน kafka ซึ่งผู้ใช้งานสามารถแก้ไขได้ผ่าน GUI
กำหนดสิทธิ์ในการเข้าถึงข้อมูลของผู้ใช้งาน
ควบคุมสิทธิ์การเข้าถึงข้อมูล โดยการกำหนดบทบาทของผู้ใช้งานอย่างชัดเจน ซึ่งครอบคลุมตั้งแต่การเข้าถึงข้อมูล, Visualization, Dashboard รวมถึงฟังก์ชันทั้งหมดในแพลตฟอร์ม
ระบบดูแลความปลอดภัยข้อมูลมาตรฐานสากล
การรักษาความปลอดภัยระดับแถว การเข้ารหัสแบบตารางหรือแบบคอลัมน์ และสามารถรวมเข้ากับ Key Management System (KMS) เพื่อเพิ่มขั้นตอนการเข้ารหัสก็ได้เช่นเดียวกัน (บริการเสริมที่ต้องปรับแต่งเพิ่มเติม)
จัดการข้อมูลครอบคลุมทั้ง Lifecycle
ปรับแต่งระดับชั้นในการเก็บรักษาข้อมูลได้ ไม่ว่าจะเป็น Hot/Warm/Cold เพื่อกำหนดประเภทการบีบอัดข้อมูล (Data compression) และประเภทการเก็บรักษาข้อมูล
รองรับการจัดเก็บข้อมูลบน Storage หลายที่
รองรับการเชื่อมโยงพื้นที่จัดเก็บข้อมูลของระบบได้หลากหลายที่ และสามารถจัดทำ Data tiering เพื่อจัดเก็บข้อมูลบน Storage ได้ตามความเหมาะสมของการใช้งาน
การจัดการข้อมูลขั้นสูง
รองรับเทคนิคการจัดการข้อมูลขั้นสูง ไม่ว่าจะเป็น Data compaction, Data compression, Data lifecycle management (Hot-Warm-Cold), Data skipping, Predicated push-down, Dynamic partition pruning และ Physical file partitioning เป็นต้น
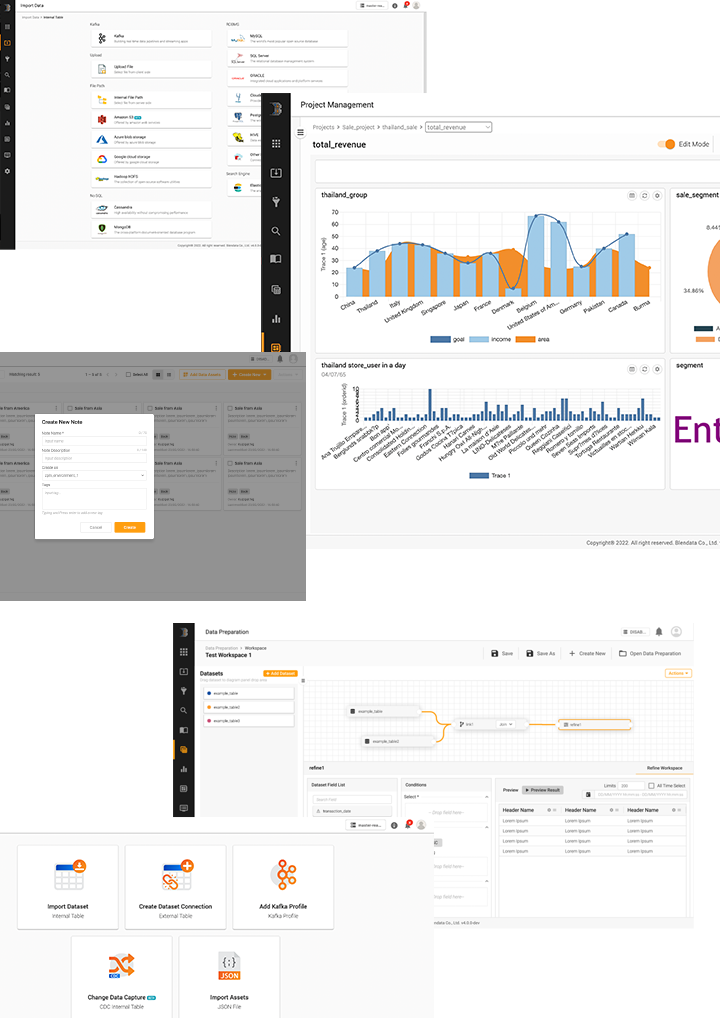
SQL Analytics
ครอบคลุมตั้งแต่ขั้นตอนการจัดเตรียม, แปลงข้อมูล (Transform), วิเคราะห์ความสัมพันธ์ (Correlate), รวมข้อมูล (Aggregate) จนถึงการวิเคราะห์ข้อมูล ผ่าน Data exploration UI ที่ช่วยให้นักวิเคราะห์ข้อมูลหรือวิศวกรข้อมูลสามารถเขียนการ Query ข้อมูลได้ด้วยไวยากรณ์ที่คุ้นเคย พร้อมฟังก์ชัน ANSI SQL + Spark SQL และช่วยให้นักวิเคราะห์ข้อมูลหรือวิศวกรข้อมูลสามารถสำรวจ จัดการ หรือกำหนดเวลาในการประมวลผลบนข้อมูลของตนเองได้
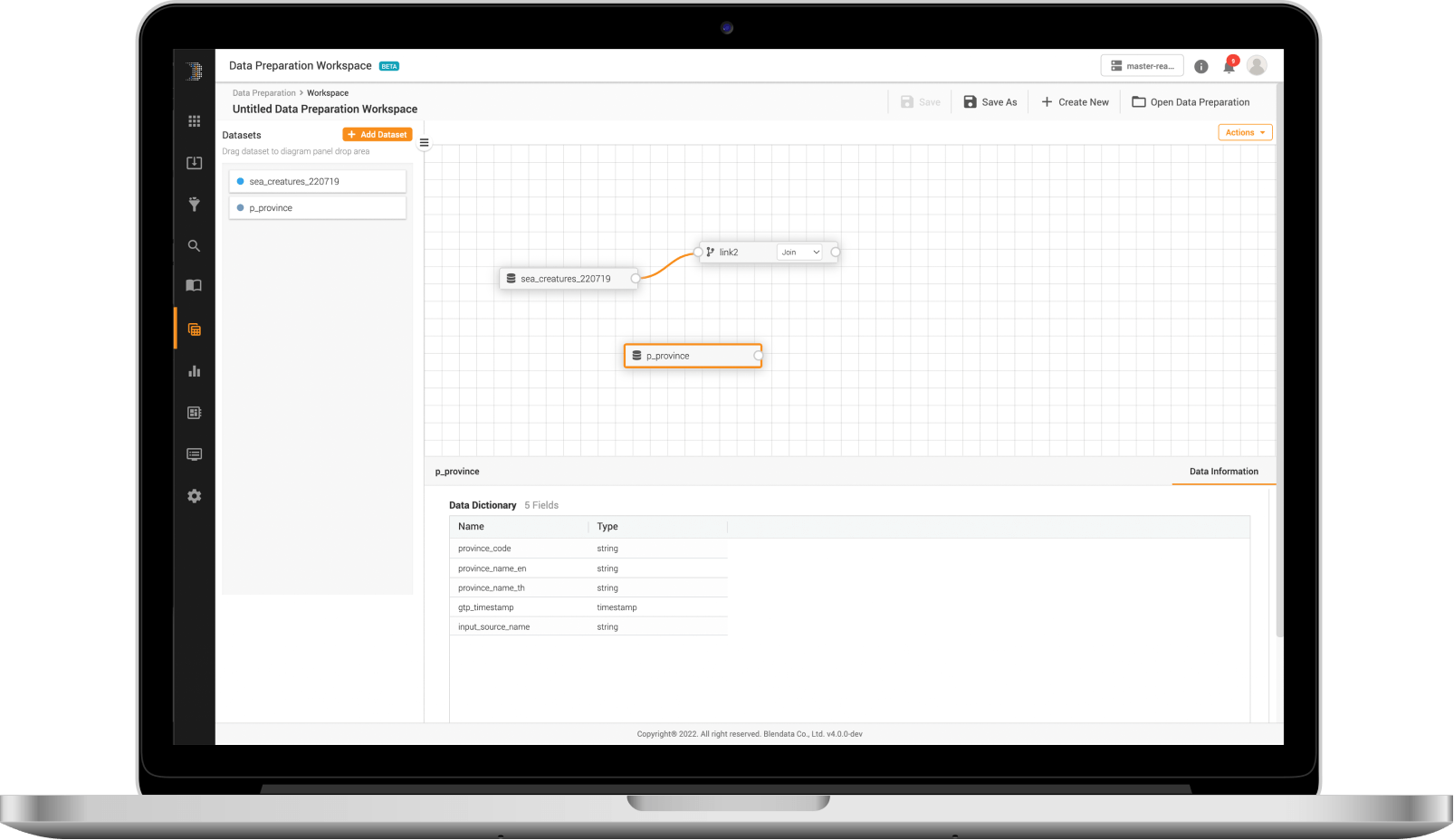
Data Preparation Workspace
สามารถจัดเตรียมข้อมูลได้ด้วย Engine และความสามารถเดียวกันกับการวิเคราะห์ SQL (Data exploration UI) แต่สามารถทำได้ด้วยวิธีที่ง่ายกว่า เพื่อรองรับผู้ใช้งานที่ไม่ถนัดด้านเทคนิค ให้สามารถจัดเตรียมข้อมูลได้ ในการเตรียมชุดข้อมูลได้แบบ Low-code/No-code ภายในเวลาไม่กี่นาที
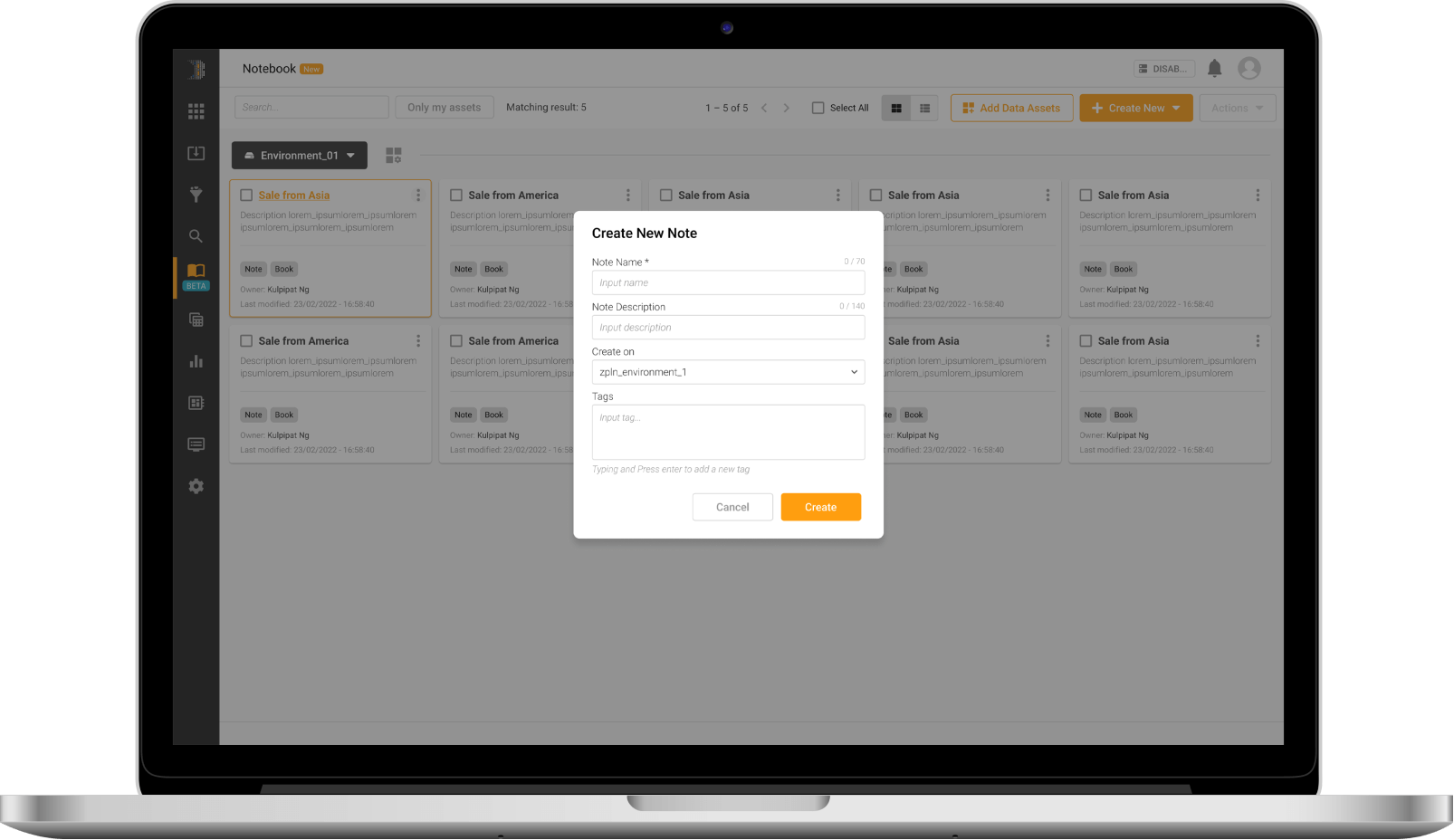
Notebook Interface
มอบประสบการณ์ที่คุ้นเคยให้กับนักวิศวกรข้อมูลและนักพัฒนา ML ด้วยหน้าจอ Interface สำหรับโน้ตบุ๊กที่รองรับภาษาสำหรับการเขียนโปรแกรมที่มีชื่อเสียงทั้งหมด ไม่ว่าจะเป็น Python, R, Scala หรือ SQL เป็นต้น
ตั้งค่าการ Run งานได้ทั้งแบบ Job Scheduler และ Chain job
สามารถตั้งค่างานให้ Run งานตามช่วงเวลาที่กำหนด ด้วยฟังก์ชัน Job scheduler ในตัวแพลตฟอร์ม และสามารถเชื่อมโยงงานทั้งหมดเข้าด้วยกันสำหรับงานที่มีความซับซ้อนได้ตั้งแต่ต้นจนจบ
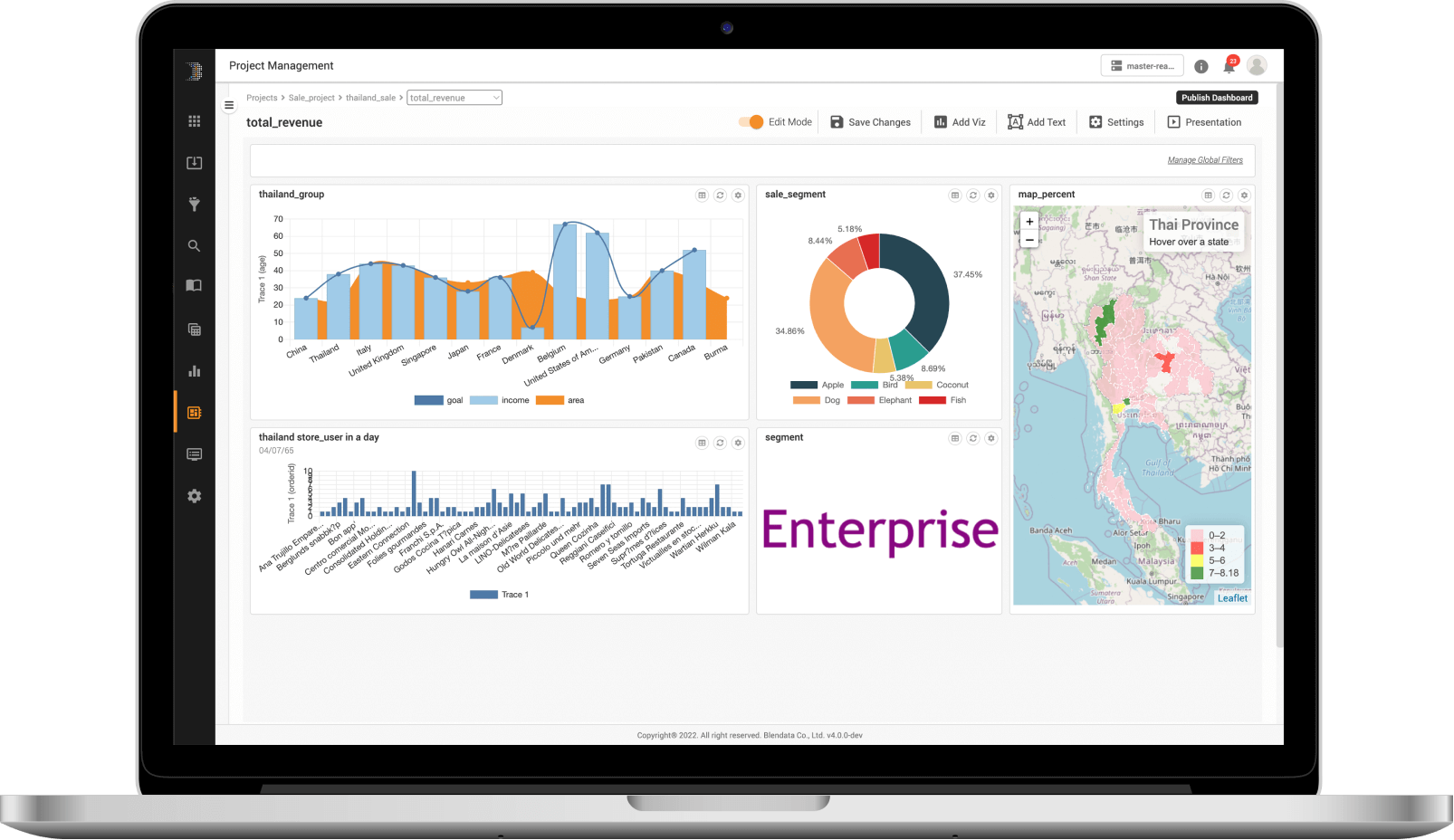
Visualization & Dashboard
เปลี่ยนผลลัพธ์ที่ได้จากการสืบค้นและวิเคราะห์ข้อมูลให้กลายเป็น Visualization ที่เข้าใจง่าย ซึ่งสามารถทำการ Drag and drop ในหน้าจอ Interface ได้ทันที โดยมีแผนภูมิการนำเสนอข้อมูลให้เลือกมากมายและสามารถจัดกลุ่ม Visualization ที่ต้องการทั้งหมดเข้าด้วยกันเป็น Dashboard ได้อย่างรวดเร็ว มาพร้อมฟังก์ชันสำหรับการกรองข้อมูลและการเจาะลึกข้อมูล (Drill-down) แล้วสร้างเป็น Big data application ที่สามารถแชร์กับเพื่อนร่วมงานได้
การแจ้งเตือน
ด้วยระบบเงื่อนไขแบบ SQL-based ที่สามารถทำการแจ้งเตือนข้อมูลผ่าน Web-console, e-mail, script หรือการเรียกใช้ API (บริการเสริมที่ต้องปรับแต่งเพิ่มเติม)
API
จัดเตรียม REST API ที่มีการรักษาความปลอดภัยด้วย OAuth2 เพื่อเรียกข้อมูลใด ๆ ด้วยคำขอ HTTP มาตรฐาน หรือเชื่อมต่อกับ Spark ODBC/Hive2server JDBC เพื่อบูรณาการร่วมกับข้อมูลในระดับ Low-level
ส่งออก (Export)
รองรับการส่งออกข้อมูลที่ผ่านการประมวลผลเป็นรูปแบบต่าง ๆ และ Downstream ประเภทต่าง ๆ ไม่ว่าจะเป็น File, Databases หรือ Cloud storage
เชื่อมต่อข้อมูลได้หลากหลาย
สามารถเชื่อมต่อและรวบรวมข้อมูลได้จากทุกแหล่งที่มา ไม่ว่าจะเป็น Flat files (CSV, JSON, Plain text, Parquet ฯลฯ ), Databases (Oracle, MS SQL, MySQL ฯลฯ ), Cloud และ Stream ผ่าน Connectors ในตัวแพลตฟอร์ม โดยไม่ต้องเขียนโค้ด
การนำเข้าข้อมูลแบบไดนามิก
นำเข้าข้อมูลจาก Flat files, Log, Databases หรือ Cloud storage ได้แบบอัตโนมัติผ่าน Connectors ในตัวแพลตฟอร์ม โดยวิธีการดังต่อไปนี้
– Scheduled replication (Batch/Stream)
– Data virtualization
– Changed data capture (CDC)
แปลงข้อมูลได้ทันทีระหว่างการนำเข้าข้อมูล (ETL)
สามารถทำการแปลงข้อมูลได้ในทันทีระหว่างการนำเข้าข้อมูล ด้วย Spark SQL พร้อมชุดฟังก์ชันการแปลงข้อมูลที่หลากหลายเพื่อรองรับข้อมูลจำนวนมหาศาล
สร้าง Schema ที่เหมาะสมกับข้อมูลได้แบบอัตโนมัติ
Engine ของ Blendata จะช่วยในการค้นหาคุณลักษณะและสร้าง Schema ได้โดยอัตโนมัติ สำหรับทุกตารางการนำเข้าข้อมูล ไม่ว่าจะเป็น File, Databases หรือการสตรีมผ่าน kafka ซึ่งผู้ใช้งานสามารถแก้ไขได้ผ่าน GUI
กำหนดสิทธิ์ในการเข้าถึงข้อมูลของผู้ใช้งาน
ควบคุมสิทธิ์การเข้าถึงข้อมูล โดยการกำหนดบทบาทของผู้ใช้งานอย่างชัดเจน ซึ่งครอบคลุมตั้งแต่การเข้าถึงข้อมูล, Visualization, Dashboard รวมถึงฟังก์ชันทั้งหมดในแพลตฟอร์ม
ระบบดูแลความปลอดภัยข้อมูลมาตรฐานสากล
การรักษาความปลอดภัยระดับแถว การเข้ารหัสแบบตารางหรือแบบคอลัมน์ และสามารถรวมเข้ากับ Key Management System (KMS) เพื่อเพิ่มขั้นตอนการเข้ารหัสก็ได้เช่นเดียวกัน (บริการเสริมที่ต้องปรับแต่งเพิ่มเติม)
จัดการข้อมูลครอบคลุมทั้ง Lifecycle
ปรับแต่งระดับชั้นในการเก็บรักษาข้อมูลได้ ไม่ว่าจะเป็น Hot/Warm/Cold เพื่อกำหนดประเภทการบีบอัดข้อมูล (Data compression) และประเภทการเก็บรักษาข้อมูล
รองรับการจัดเก็บข้อมูลบน Storage หลายที่
รองรับการเชื่อมโยงพื้นที่จัดเก็บข้อมูลของระบบได้หลากหลายที่ และสามารถจัดทำ Data tiering เพื่อจัดเก็บข้อมูลบน Storage ได้ตามความเหมาะสมของการใช้งาน
การจัดการข้อมูลขั้นสูง
รองรับเทคนิคการจัดการข้อมูลขั้นสูง ไม่ว่าจะเป็น Data compaction, Data compression, Data lifecycle management (Hot-Warm-Cold), Data skipping, Predicated push-down, Dynamic partition pruning และ Physical file partitioning เป็นต้น
SQL Analytics
ครอบคลุมตั้งแต่ขั้นตอนการจัดเตรียม, แปลงข้อมูล (Transform), วิเคราะห์ความสัมพันธ์ (Correlate), รวมข้อมูล (Aggregate) จนถึงการวิเคราะห์ข้อมูล ผ่าน Data exploration UI ที่ช่วยให้นักวิเคราะห์ข้อมูลหรือวิศวกรข้อมูลสามารถเขียนการ Query ข้อมูลได้ด้วยไวยากรณ์ที่คุ้นเคย พร้อมฟังก์ชัน ANSI SQL + Spark SQL และช่วยให้นักวิเคราะห์ข้อมูลหรือวิศวกรข้อมูลสามารถสำรวจ จัดการ หรือกำหนดเวลาในการประมวลผลบนข้อมูลของตนเองได้
Data Preparation Workspace
สามารถจัดเตรียมข้อมูลได้ด้วย Engine และความสามารถเดียวกันกับการวิเคราะห์ SQL (Data exploration UI) แต่สามารถทำได้ด้วยวิธีที่ง่ายกว่า เพื่อรองรับผู้ใช้งานที่ไม่ถนัดด้านเทคนิค ให้สามารถจัดเตรียมข้อมูลได้ ในการเตรียมชุดข้อมูลได้แบบ Low-code/No-code ภายในเวลาไม่กี่นาที
Notebook Interface
มอบประสบการณ์ที่คุ้นเคยให้กับนักวิศวกรข้อมูลและนักพัฒนา ML ด้วยหน้าจอ Interface สำหรับโน้ตบุ๊กที่รองรับภาษาสำหรับการเขียนโปรแกรมที่มีชื่อเสียงทั้งหมด ไม่ว่าจะเป็น Python, R, Scala หรือ SQL เป็นต้น
ตั้งค่าการ Run งานได้ทั้งแบบ Job Scheduler และ Chain job
สามารถตั้งค่างานให้ Run งานตามช่วงเวลาที่กำหนด ด้วยฟังก์ชัน Job scheduler ในตัวแพลตฟอร์ม และสามารถเชื่อมโยงงานทั้งหมดเข้าด้วยกันสำหรับงานที่มีความซับซ้อนได้ตั้งแต่ต้นจนจบ
Visualization & Dashboard
เปลี่ยนผลลัพธ์ที่ได้จากการสืบค้นและวิเคราะห์ข้อมูลให้กลายเป็น Visualization ที่เข้าใจง่าย ซึ่งสามารถทำการ Drag and drop ในหน้าจอ Interface ได้ทันที โดยมีแผนภูมิการนำเสนอข้อมูลให้เลือกมากมายและสามารถจัดกลุ่ม Visualization ที่ต้องการทั้งหมดเข้าด้วยกันเป็น Dashboard ได้อย่างรวดเร็ว มาพร้อมฟังก์ชันสำหรับการกรองข้อมูลและการเจาะลึกข้อมูล (Drill-down) แล้วสร้างเป็น Big data application ที่สามารถแชร์กับเพื่อนร่วมงานได้
การแจ้งเตือน
ด้วยระบบเงื่อนไขแบบ SQL-based ที่สามารถทำการแจ้งเตือนข้อมูลผ่าน Web-console, e-mail, script หรือการเรียกใช้ API (บริการเสริมที่ต้องปรับแต่งเพิ่มเติม)
API
จัดเตรียม REST API ที่มีการรักษาความปลอดภัยด้วย OAuth2 เพื่อเรียกข้อมูลใด ๆ ด้วยคำขอ HTTP มาตรฐาน หรือเชื่อมต่อกับ Spark ODBC/Hive2server JDBC เพื่อบูรณาการร่วมกับข้อมูลในระดับ Low-level
ส่งออก (Export)
รองรับการส่งออกข้อมูลที่ผ่านการประมวลผลเป็นรูปแบบต่าง ๆ และ Downstream ประเภทต่าง ๆ ไม่ว่าจะเป็น File, Databases หรือ Cloud storage




We use cookie to give you the best online experience Please let us know if you agree to all of these cookie.

We use cookie to give you the best online experience Please let us know if you agree to all of these cookie.