 Less effort,
Less effort, Cutting edge big data
Cutting edge big data Connect everything,
Connect everything, Open,
Open,Drive your business with data
Drive your business with data
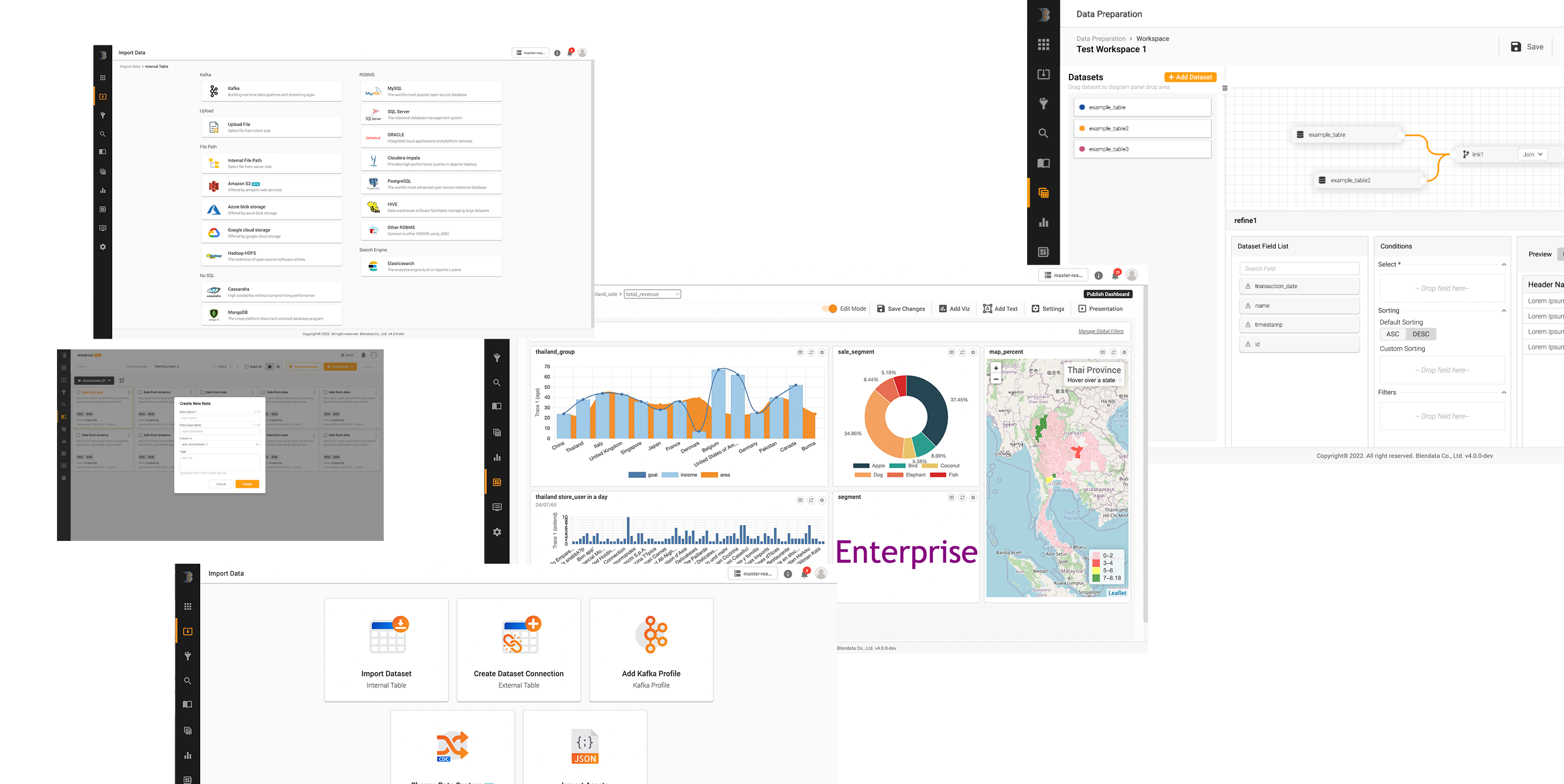

It streamlines data management, reduces installation time, and allows you to manage all processes under one platform, from data integration to utilization. It is both engineering and end-user low-code or no-code solutions that do not require any coding knowledge.

Say goodbye to big data single-server expansions. The platform works on a new-gen decoupling compute & storage architecture powered by Blendata’s proprietary distributed in-memory processing. It developed from Apache Spark with a processing speed of 1.5 times higher.

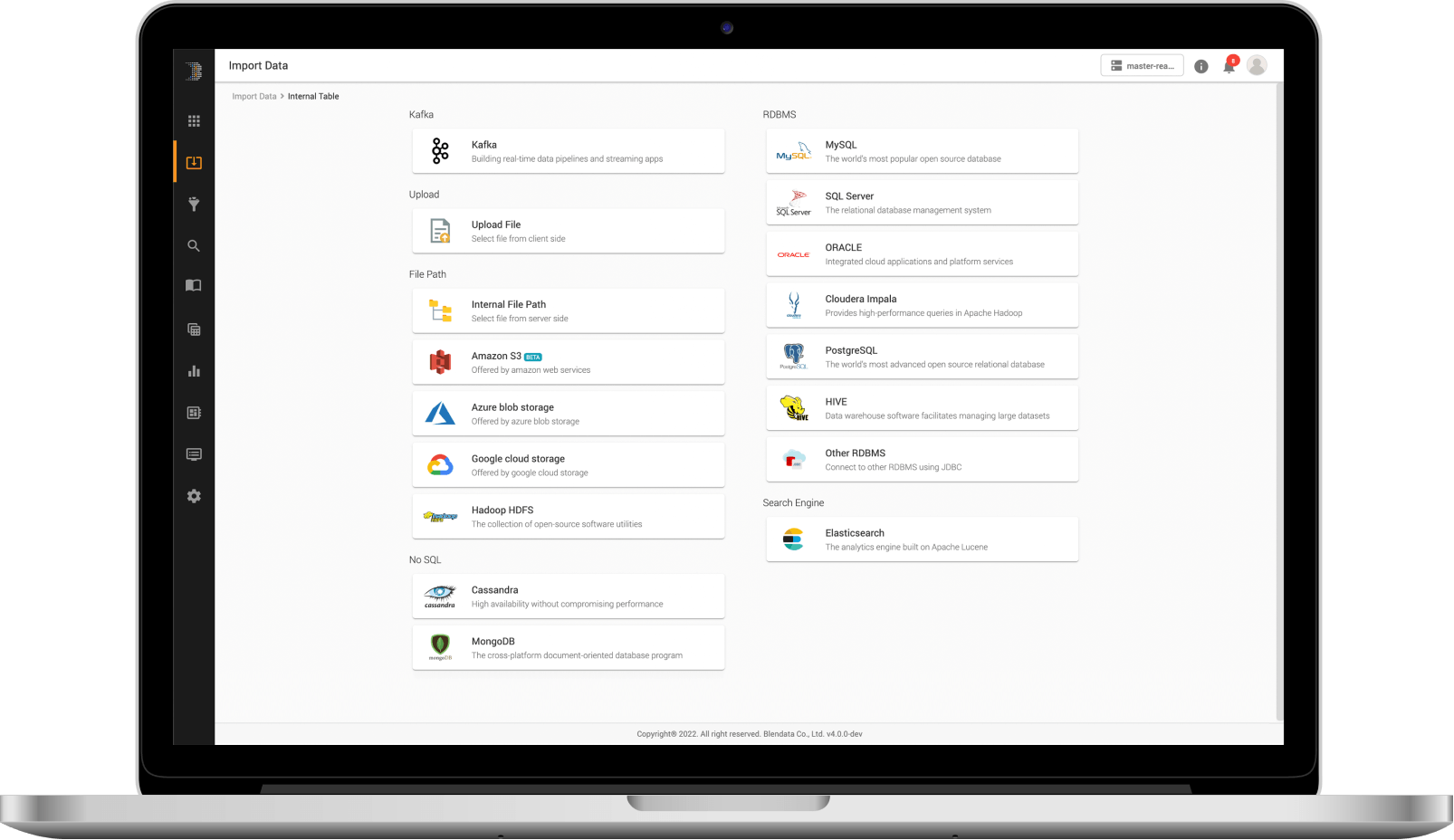
Multi-interface connections, whether structured, semi-structured, and unstructured (text-based), or from cloud storage sites such as Amazon S3, Azure Blob, or on-premise environments such as flat files (CSV, JSON, text), logs, Kafka, HDFS, or enterprise databases (Oracle, MS SQL Server, MongoDB, etc.) through dynamic data ingestion.

Being an open design platform from the beginning, organizations may enjoy data usage or platform functions through an API that supports REST API, ODBC/JDBC, or direct data access through open format files. Moreover, all connections, in-transit, and at-rest data are protected against unauthorized access by SSL/TLS standard, columnar, and in-transit encryptions, OAuth 2.0 user/role-based access control authentication and authorisation.
It streamlines data management, reduces installation time, and allows you to manage all processes under one platform, from data integration to utilization. It is both engineering and end-user low-code or no-code solutions that do not require any coding knowledge.
Say goodbye to big data single-server expansions. The platform works on a new-gen decoupling compute & storage architecture powered by Blendata’s proprietary Distribute In-Memory Twin Processors. It developed from Apache Spark with a processing speed of 1.5 times higher.
Multi-interface connections whether structured, semi-structured, and unstructured (text-based), or from cloud storage sites such as Amazon S3, Azure Blob, or on-premise environments such as flat files (CSV, JSON, text), logs, Kafka, HDFS, or enterprise databases (Oracle, MS SQL Server, MongoDB, etc.) through dynamic data ingestion.
An open design platform that allows organizations to enjoy data usage or other platform functions through an API that supports REST API, ODBC/JDBC, or direct data access through open format files. Moreover, all connections, including in-transit, and at-rest data are protected against unauthorized access by SSL/TLS standard, columnar, and in-transit encryptions, OAuth 2.0 user/role-based access control authentication, and authorization.




Dynamic data import
Import data from flat files, log databases, or cloud storage automatically through built-in connectors in the following schemes.
Extract, transform, and load upon import (ETL)
Transforms data upon importing with Spark SQL comes with various data transform functions to support big data.
Automatic schema creation
The engine of Blendata automatically searches the attributes and creates the schema for all import tables including files, databases, or streaming through Kafka is modifiable by the user through GUI.
Customizable user access
Customizable access rights in clear detail covering data access, visualization, dashboard, and all functions on the platform.
Global standard data security
Row-level security, table or columnar encryptions, and integration with Key Management System (KMS) externally to enhance the encryptions process (additional option).
Lifecycle Management
Customizable data tiering level whether Hot/Warm/Cold to determine the data compression and data retention category.
Multi-location storage
Support multi-storage location interlinking and multiple-device data tiering.
Advanced data management
Support advanced data management such as data compaction, data compression, data lifecycle management (hot-warm-cold), data skipping, predicated push-down, dynamic partition pruning, and physical file partitioning.
SQL Analytics
Cover data preparations, transformations, correlations, aggregations, and data exploration UI that enables analyzers or engineers to query with familiar grammar, together with ANSI SQL + Spark SQL functions, and allows analyzers or engineers to survey, manage, or schedule processing job for their own data.
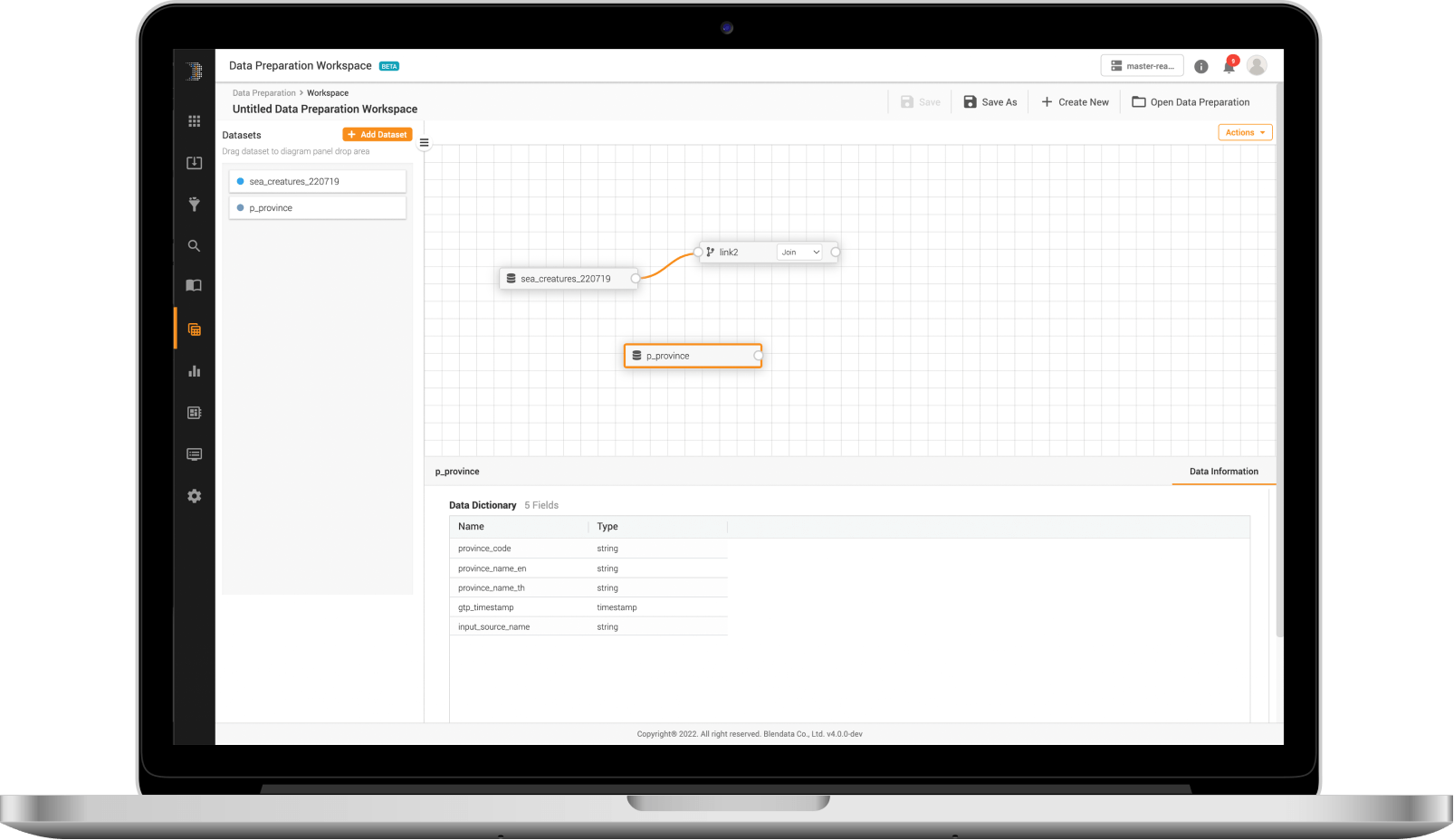
Data Preparation Workspace
Offer the same data preparation engine and functions as SQL analysis (data exploration UI) but with a more user-friendly approach to support low-code/no-code data preparations for non-technical users within a matter of seconds.
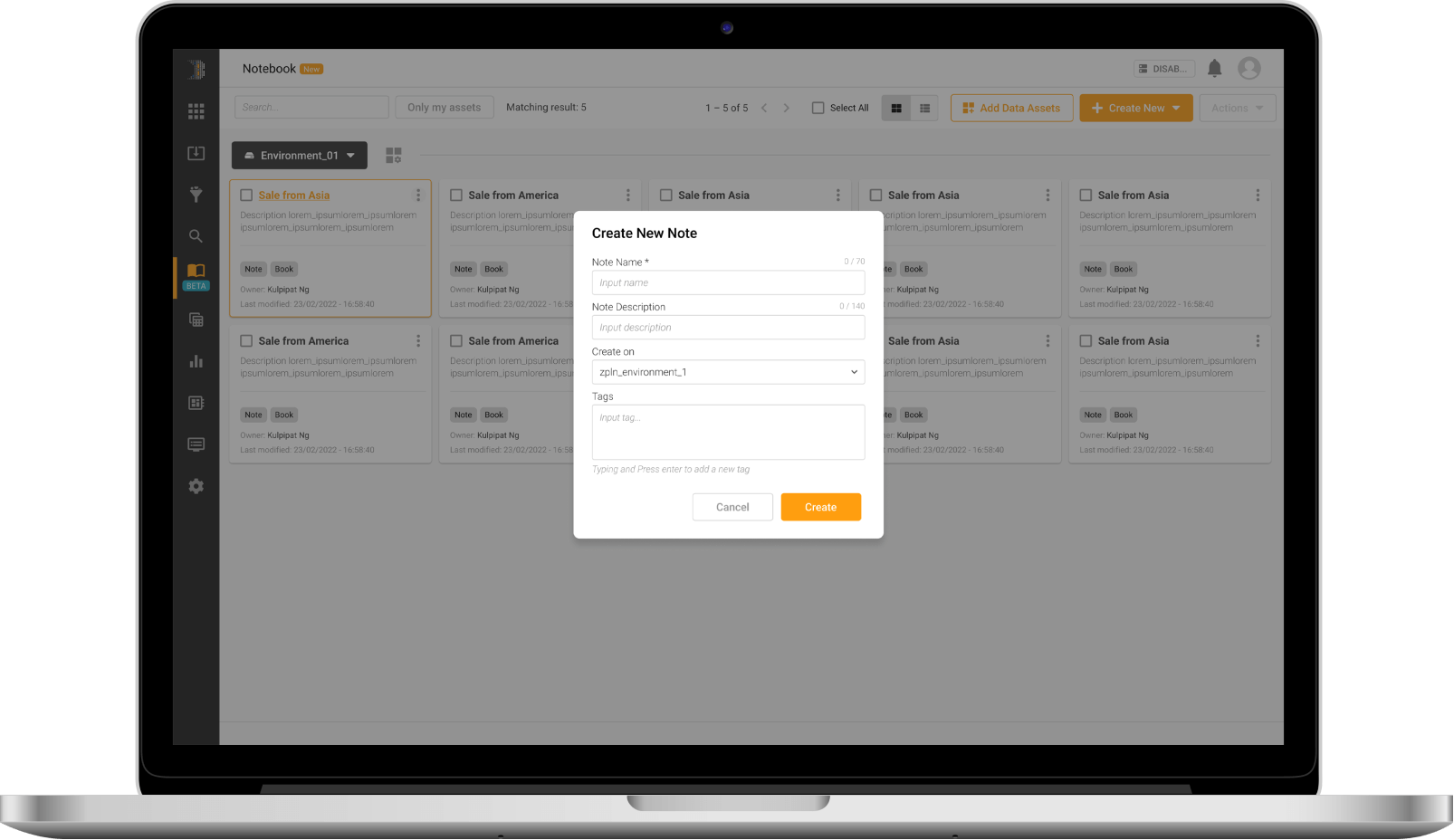
Notebook Interface
Offer a familiar experience to data engineers and ML developers with a notebook interface that supports all well-known programming languages, such as Python, R, Scala, and SQL.
Job scheduler and chain job setting
Set tasks to run on a schedule with the built-in Job Scheduler function and link all tasks together for complex jobs from the beginning to the end.
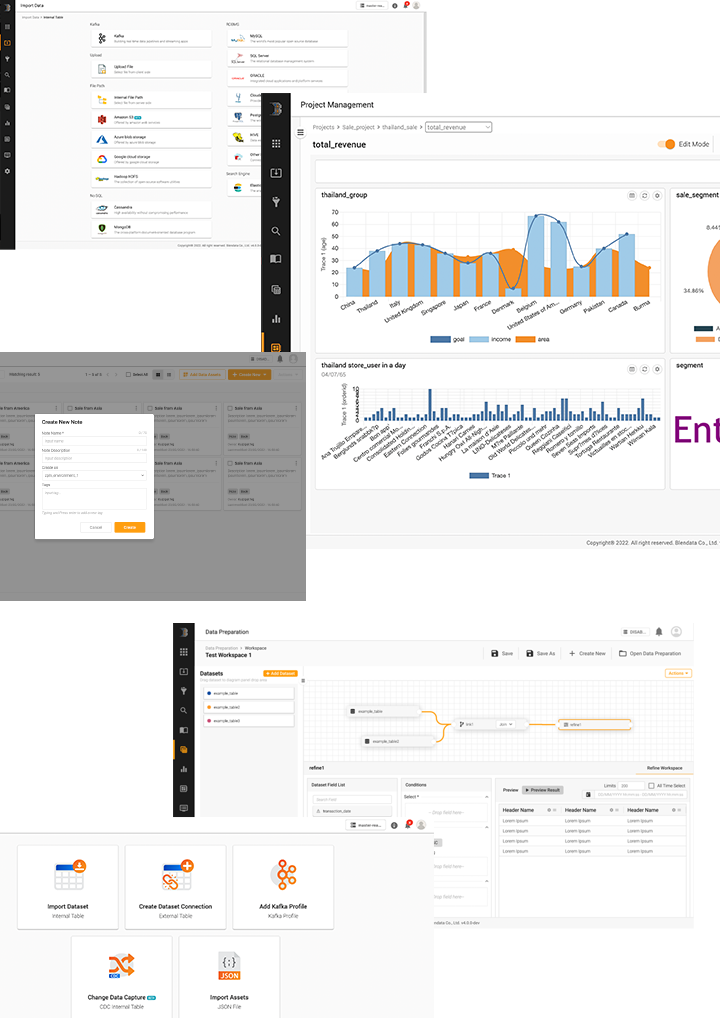
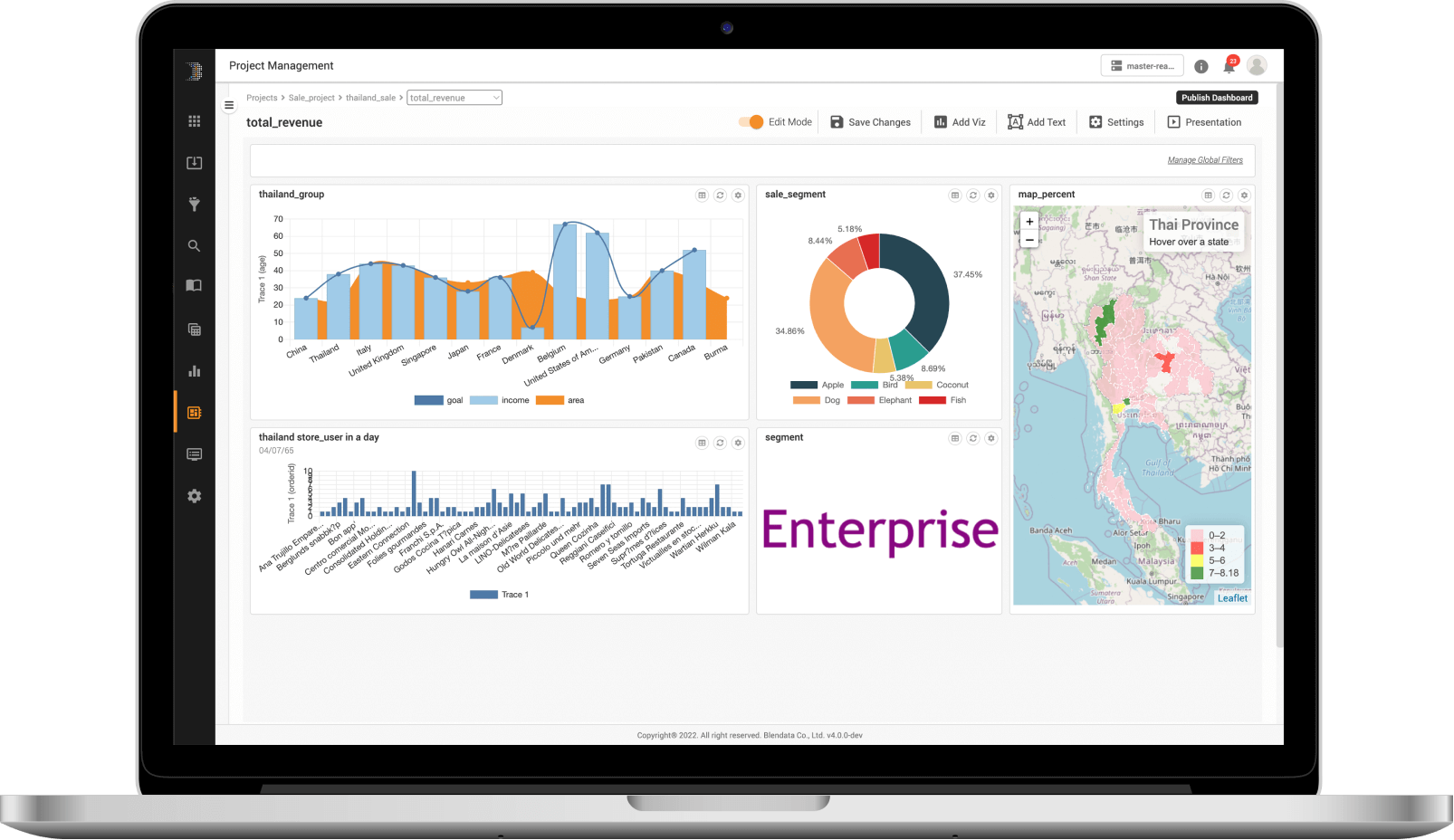
Visualization & Dashboard
Transform search and analysis results into user-friendly visualization that can be dragged and dropped directly on the interface with many presentation charts available which can be categorized on a dashboard right away. It comes with data filtering and drill-down functions that can be created as a big data application ready to be shared among co-workers.
Notification
SQL-based notifications are to be made via the web console, email, script, or API (additional option).
API
Prepare REST API with the OAuth2 authentication system to fetch data by using standard HTTP queries or linking with Spark ODBC/Hive2server JDBC to integrate data at a low level.
Export
Support exports of processed data in many formats and downstream media such as files, databases, or cloud storage.
Dynamic data import
Import data from flat files, log databases, or cloud storage automatically through built-in connectors in the following schemes.
Extract, transform, and load upon import (ETL)
Transforms data upon importing with Spark SQL comes with various data transform functions to support big data.
Automatic schema creation
The engine of Blendata automatically searches the attributes and creates the schema for all import tables including files, databases, or streaming through Kafka is modifiable by the user through GUI.
Customizable user access
Customizable access rights in clear detail covering data access, visualization, dashboard, and all functions on the platform.
Global standard data security
Row-level security, table or columnar encryptions, and integration with Key Management System (KMS) externally to enhance the encryptions process (additional option).
Lifecycle Management
Customizable data tiering level whether Hot/Warm/Cold to determine the data compression and data retention category.
Multi-location storage
Support multi-storage location interlinking and multiple-device data tiering.
Advanced data management
Support advanced data management such as data compaction, data compression, data lifecycle management (hot-warm-cold), data skipping, predicated push-down, dynamic partition pruning, and physical file partitioning.
SQL Analytics
Cover data preparations, transformations, correlations, aggregations, and data exploration UI that enables analyzers or engineers to query with familiar grammar, together with ANSI SQL + Spark SQL functions, and allows analyzers or engineers to survey, manage, or schedule processing job for their own data.
Data Preparation Workspace
Offer the same data preparation engine and functions as SQL analysis (data exploration UI) but with a more user-friendly approach to support low-code/no-code data preparations for non-technical users within a matter of seconds.
Notebook Interface
Offer a familiar experience to data engineers and ML developers with a notebook interface that supports all well-known programming languages, such as Python, R, Scala, and SQL.
Job scheduler and chain job setting
Set tasks to run on a schedule with the built-in Job Scheduler function and link all tasks together for complex jobs from the beginning to the end.
Visualization & Dashboard
Transform search and analysis results into user-friendly visualization that can be dragged and dropped directly on the interface with many presentation charts available which can be categorized on a dashboard right away. It comes with data filtering and drill-down functions that can be created as a big data application ready to be shared among co-workers.
Notification
SQL-based notifications are to be made via the web console, email, script, or API (additional option).
API
Prepare REST API with the OAuth2 authentication system to fetch data by using standard HTTP queries or linking with Spark ODBC/Hive2server JDBC to integrate data at a low level.
Export
Support exports of processed data in many formats and downstream media such as files, databases, or cloud storage.




We use cookie to give you the best online experience Please let us know if you agree to all of these cookie.

We use cookie to give you the best online experience Please let us know if you agree to all of these cookie.